Research
Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition
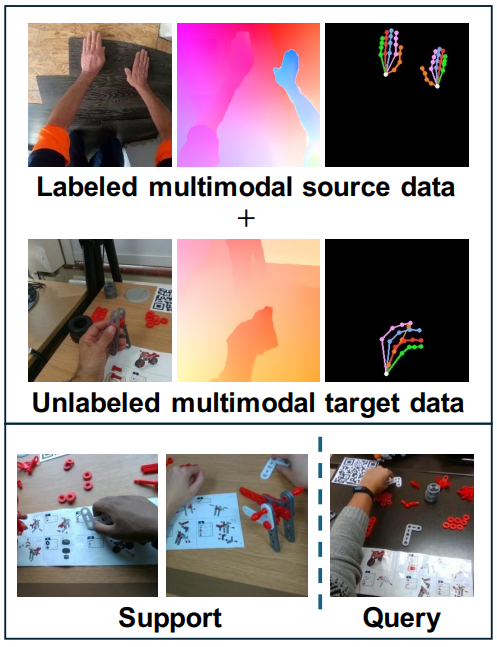
We address a novel cross-domain few-shot learning task (CD-FSL) with multimodal input and unlabeled target data for egocentric action recognition. This paper simultaneously tackles two critical challenges associated with egocentric action recognition in CD-FSL settings:(1) the extreme domain gap in egocentric videos (e.g., daily life vs. industrial domain) and (2) the computational cost for real-world applications. We propose MM-CDFSL, a domain-adaptive and computationally efficient approach designed to enhance adaptability to the target domain and improve inference speed. To address the first challenge, we propose the incorporation of multimodal distillation into the student RGB model using teacher models. Each teacher model is trained independently on source and target data for its respective modality. Leveraging only unlabeled target data during multimodal distillation enhances the student model’s adaptability to the target domain. We further introduce ensemble masked inference, a technique that reduces the number of input tokens through masking. In this approach, ensemble prediction mitigates the performance degradation caused by masking, effectively addressing the second issue. Our approach outperformed the state-of-the-art CD-FSL approaches with a substantial margin on multiple egocentric datasets, improving by an average of 6.12/6.10 points for 1-shot/5-shot settings while achieving 2.2 times faster inference speed.
ECCV 2024
Masashi Hatano, Ryo Hachiuma, Ryo Fujii, Hideo Saito
[Paper] [Code] [Project Page] [YouTube]
Event-based Blur Kernel Estimation For Blind Motion Deblurring
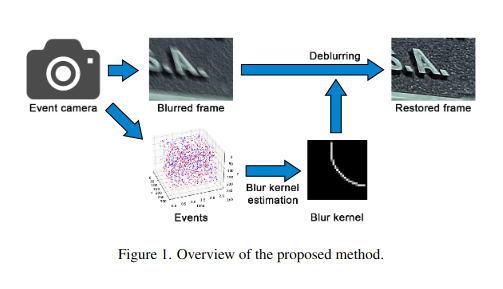
This method uses an event camera, which captures high-temporal-resolution data on pixel luminance changes, along with a conventional camera to capture the input blurred image. By analyzing the event data stream, the proposed method estimates the 2D motion of the blurred image at short intervals during the exposure time, and integrates this information to estimate a variety of complex blur motions. With the estimated blur kernel, the input blurred image can be deblurred using deconvolution.
CVPR 2023
Takuya Nakabayashi, Kunihiro Hasegawa, Masakazu Matsugu, Hideo Saito
[Paper]
3D Shape Estimation of Wires From 3D X-Ray CT Images of Electrical Cables
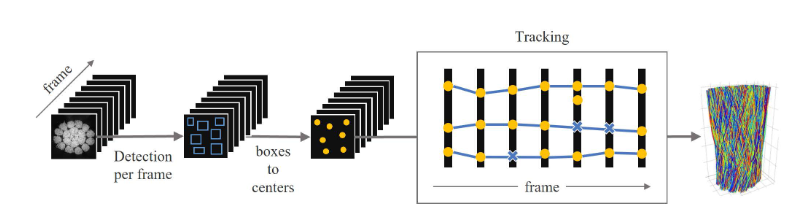
In this study, we propose a new method to associate wires using particle tracking techniques. The proposed method performs
wire tracking in two steps, linking detected wire positions between adjacent frames and connecting segmented wires across frames.
QCAV 2023
Shiori Ueda, Kanon Sato, Hideo Saito, Yutaka Hoshina
[Paper]
Incremental Class Discovery for Semantic Segmentation with RGBD Sensing
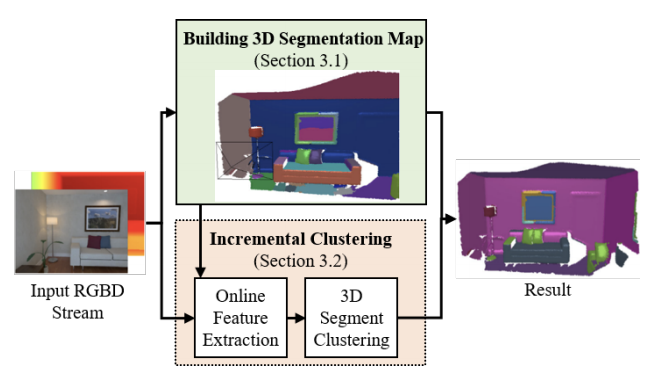
This work addresses the task of open world semantic segmentation using RGBD sensing to discover new semantic classes over time. Although there are many types of objects in the real-word, current semantic segmentation methods make a closed world assumption and are trained only to segment a limited number of object classes. Towards a more open world approach, we propose a novel method that incrementally learns new classes for image segmentation.
ICCV 2019
Yoshikatsu Nakajima, Byeongkeun Kang, Hideo Saito, Kris Kitani
DetectFusion: Detecting and Segmenting Both Known and Unknown Dynamic Objects in Real-time SLAM
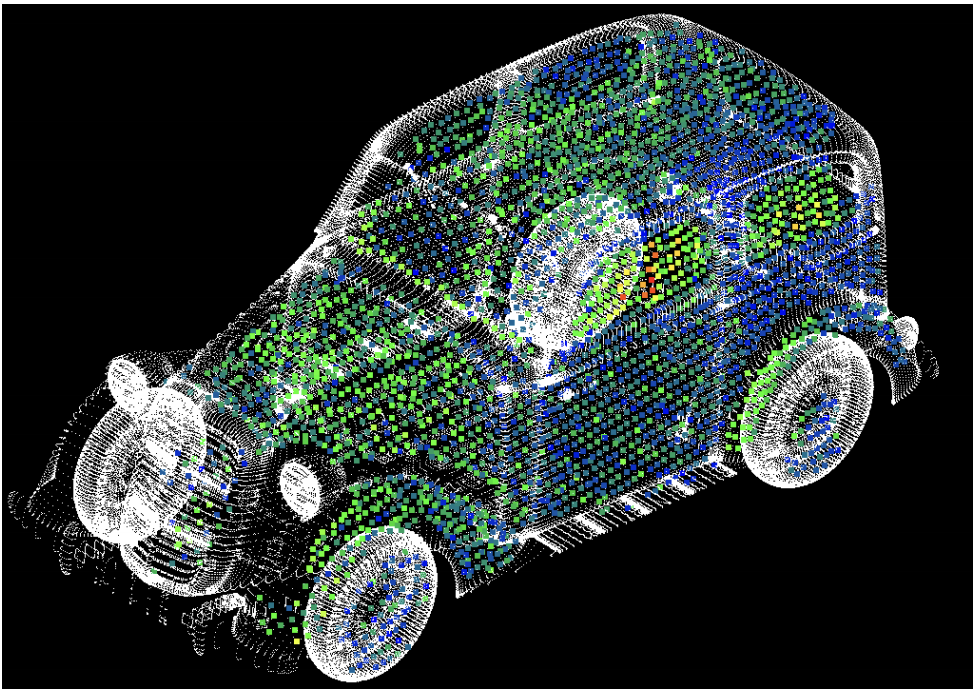
We present DetectFusion, an RGB-D SLAM system that runs in real time and can robustly handle semantically known and unknown objects that can move dynamically in the scene. Our system detects, segments and assigns semantic class labels to known objects in the scene, while tracking and reconstructing them even when they move independently in front of the monocular camera.
BMVC 2019
Ryo Hachiuma, Christian Pirchheim, Dieter Schmalstieg, Hideo Saito
EventNet: Asynchronous Recursive Event Processing
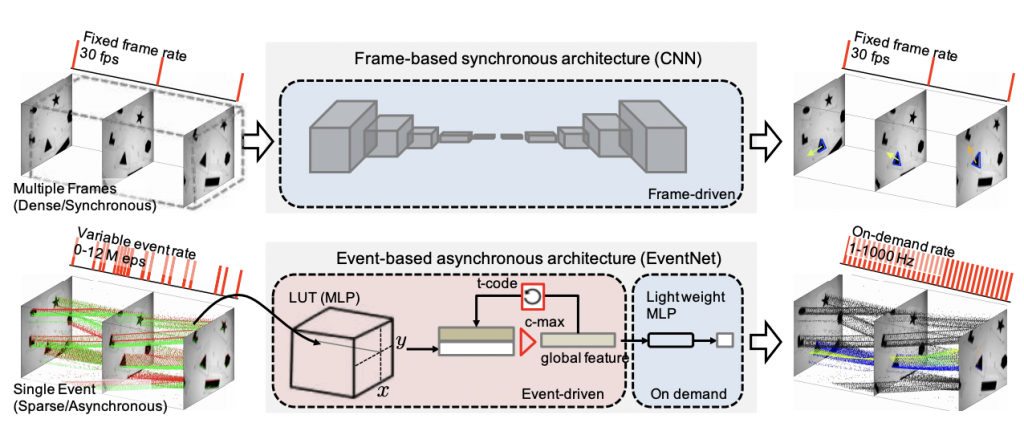
Event cameras are bio-inspired vision sensors that mimic retinas to asynchronously report per-pixel intensity changes rather than outputting an actual intensity image at regular intervals. This new paradigm of image sensor offers significant potential advantages; namely, sparse and nonredundant data representation. Unfortunately, however, most of the existing artificial neural network architectures, such as a CNN, require dense synchronous input data, and therefore, cannot make use of the sparseness of the data. We propose EventNet, a neural network designed for real-time processing of asynchronous event streams in a recursive and event-wise manner.
CVPR 2019
Yusuke Sekikawa, Kosuke Hara, Hideo Saito
Fast and Accurate Semantic Mapping through Geometric-based Incremental Segmentation
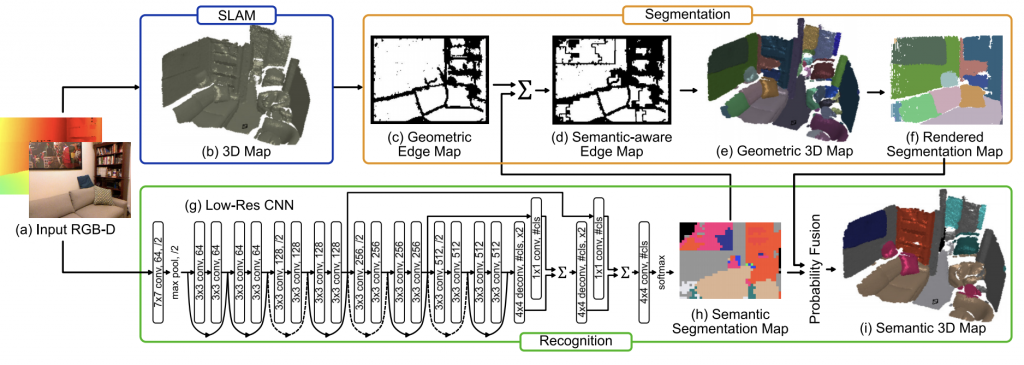
We propose an efficient and scalable method for incrementally building a dense, semantically annotated 3D map in real-time. The proposed method assigns class probabilities to each region, not each element (e.g., surfel and voxel), of the 3D map which is built up through a robust SLAM framework and incrementally segmented with a geometric-based segmentation method.
IROS 2018
Yoshikatsu Nakajima, Keisuke Tateno, Federico Tombari, Hideo Saito
Constant Velocity 3D Convolution
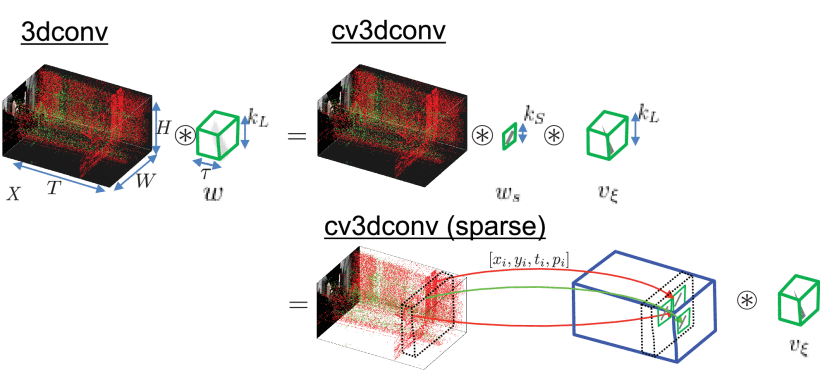
We propose a novel 3-D convolution method, cv3dconv, for extracting spatiotemporal features from videos. It reduces the number of sum-of-products operations in 3-D convolution by thousands of times by assuming the constant moving velocity of the features.
3DV 2018
Yusuke Sekikawa, Kohta Ishikawa, Kosuke Hara, Yuuichi Yoshida, Koichiro Suzuki, Ikuro Sato, Hideo Saito