3D context
Three-dimensional technologies, as the next revolution in visual technology, promises to bring to the customers a new generation of services. The improvement of multiview technologies raised interest in 3D television (3DTV) and in free viewpoint video (FVV). While 3DTV offers depth perception of program entertainments without wearing special additional glasses, FVV allows the user to freely change his viewpoint position and viewpoint direction around a 3D reconstructed scene. Another target fields can be expected, like Digital Cinema, IMAX theaters, medicine, dentistry, air-traffic control, military technologies, computer games, and more.
In the meantime, the development of digital TV and 3D displays has largely improved recently, and thus, created a wide interest in multiview applications. Sharp, Sony and Sanyo, three Japanese companies, have formed in march 2003 the 3D Consortium in order to help the development of 3D technologies. Japan seems to be again among the first countries in the world to put 3DTV in the market, and to develop FVV applications as discussed above. Japan plans to make it a commercial reality by 2020.
Video context
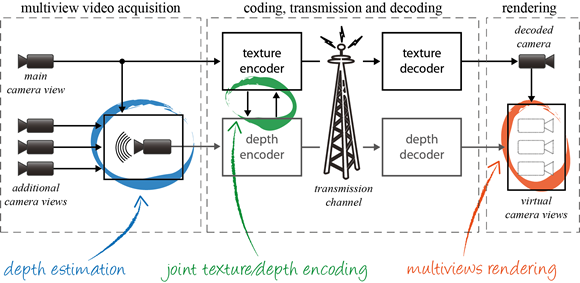
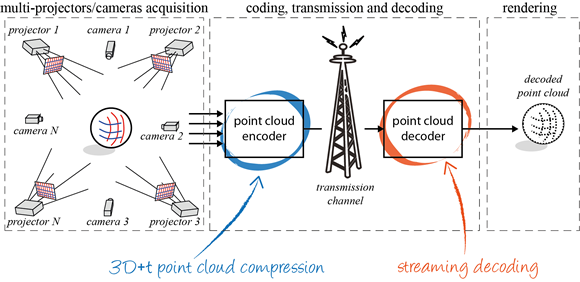
In particular, capturing with multiple cameras, processing and coding the acquired multiview video have become an active research topic. The huge amount of data to be processed by multiview applications raised the problem of efficient encoding of a multiview video sequence.
High compression efficiency is achieved by exploits both spatial and temporal redundancies. Temporally adjacent frames are often high correlated. In the spatial domain neighboring pixels are very similar especially in homogeneous area. A video encoder carries out three main functional units: the temporal prediction, the spatial transformation and the entropy coding to produce a compressed binary stream.
The temporal prediction leads to estimate the motion between adjacent temporal frames. The spatial transformation removes the spatial redundancies into a transform domain and provides a more compact representation of the date into a small number of values. The elements issues from the temporal prediction and the spatial transformation, denoted as symbols, are converted into a binary code and compressed by the entropy coder. The entropy encoder removes the statistical redundancy in the data.
Keywords : video-plus-depth, MVC, DIBR, FVV, 3DTV, MMA Team, TSI, Telecom ParisTech